ディープラーニングシステム
概要
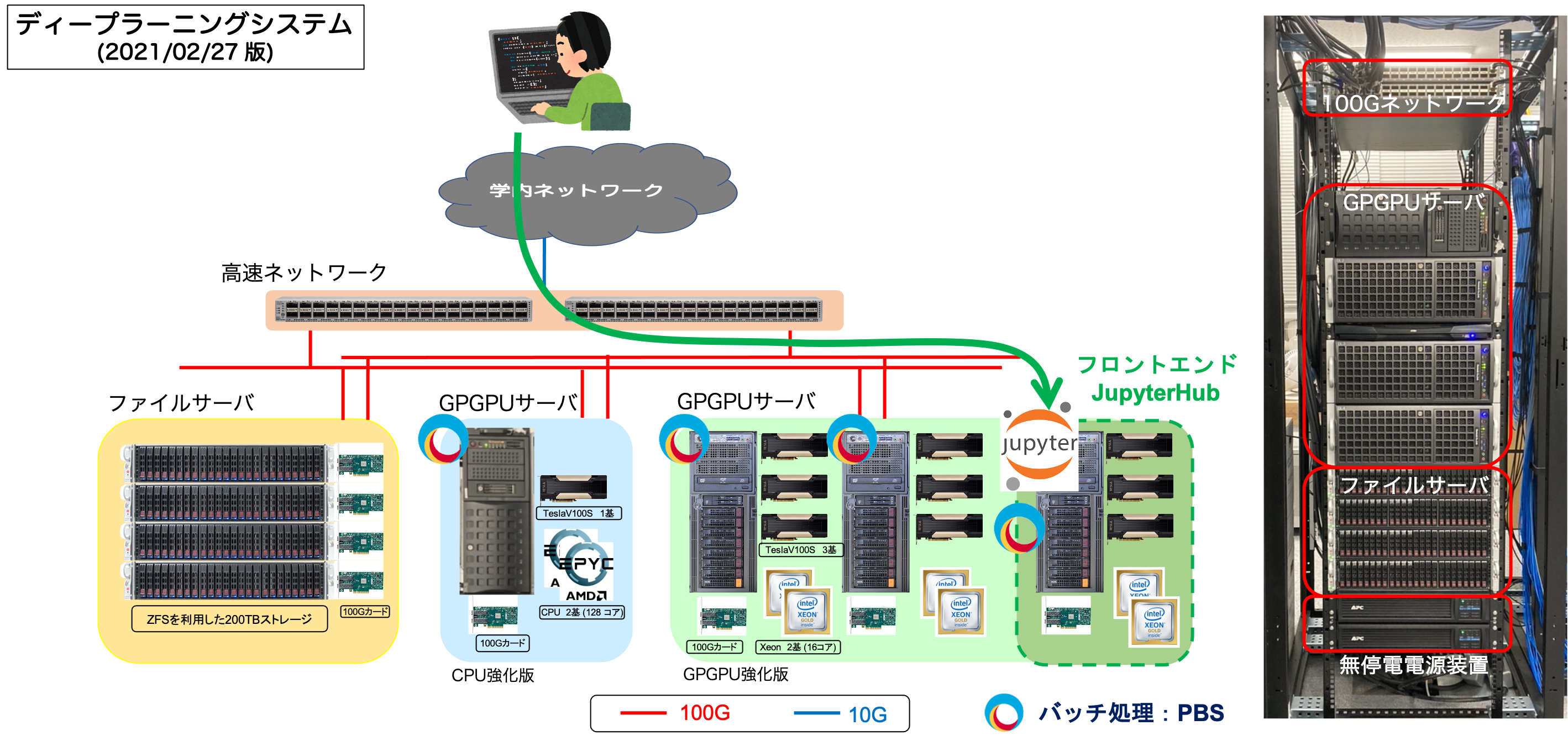
経緯
スペック
- 100G ネットワーク : CISCO 製 Nexsus 9336C-FX2, 2 台 (冗長構成)
- ncfs1: ログインノード・ファイルサーバ : Newtech 製 NCDBX004T12SDS2T14
- SSD 2 TB x 24 (Software RAID), 12 台
- ncsv1: 計算ノード
- CPU: AMD EPYC7702 x 2, GPGPU: Tesla V100S-32G x 2
- ncsv2: 計算ノード
- CPU: Intel Xeon Gold6234 x 2, GPGPU: Tesla A100S 80G x 3
- ncsv3: 計算ノード
- CPU: Intel Xeon Gold6234 x 2, GPGPU: Tesla V100S-32G x 4
- ncsv5: 計算ノード
- CPU: Intel Xeon Gold6226R x 2, GPGPU: Tesla A40 x 2
- ncsv4: JupyterHub
- CPU: Intel Xeon Gold6234 x 2, GPGPU: Tesla V100S-32G x 4
利用形態
以下の 2 つの形式によりプログラムを実行することが可能です.
JupyterLab を用いたインタラクティブ処理
サーバには V100 GPU が合計 4 基搭載されています.1 つのランは最大 24 時間です
http://jupyter.matsue-ct.ac.jp:8000
利用時には以下の 2 つを必ず行ってください.
GPU の使用状態の確認 !nvidia-smi nvidia-smi の結果から利用されていない GPU の ID を把握し,その利用を宣言する (以下では, ID=2 を利用) import os os.environ["CUDA_VISIBLE_DEVICES"]="2"
Slurm を用いたバッチ処理
ターミナルから SSH でログインしてください.
$ ssh -l (ユーザ名) slurm.matsue-ct.ac.jp
キューは以下の通り. 最大 72 時間.
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST short* up 1:00:00 3 idle ncsv[2-3,5] <-- 学生演習用.最大 1 時間 long up 3-00:00:00 1 idle ncsv1 <-- 長時間計算用 v100 up 3-00:00:00 2 idle ncsv[1,3] <-- V100 GPU 用 (6基) a100 up 3-00:00:00 1 idle ncsv2 <-- A100 GPU 用 (3基) a40 up 3-00:00:00 1 idle ncsv5 <-- A40 GPU 用 (2基)