Quick Start (インタラクティブ処理)
基本的な使い方
ユーザは Web インターフェイス (JupyterLab) から計算を実行してください. 以下の URL からアクセスできます.
基本的に NoteBook から対話的にプログラムを実行するのが良いですが, ターミナルからコマンドでプログラムを実行することもできます. また,ファイルのアップロード,ディレクトリの作成, ファイルの編集といった作業も JupyterLab から行うことができます.
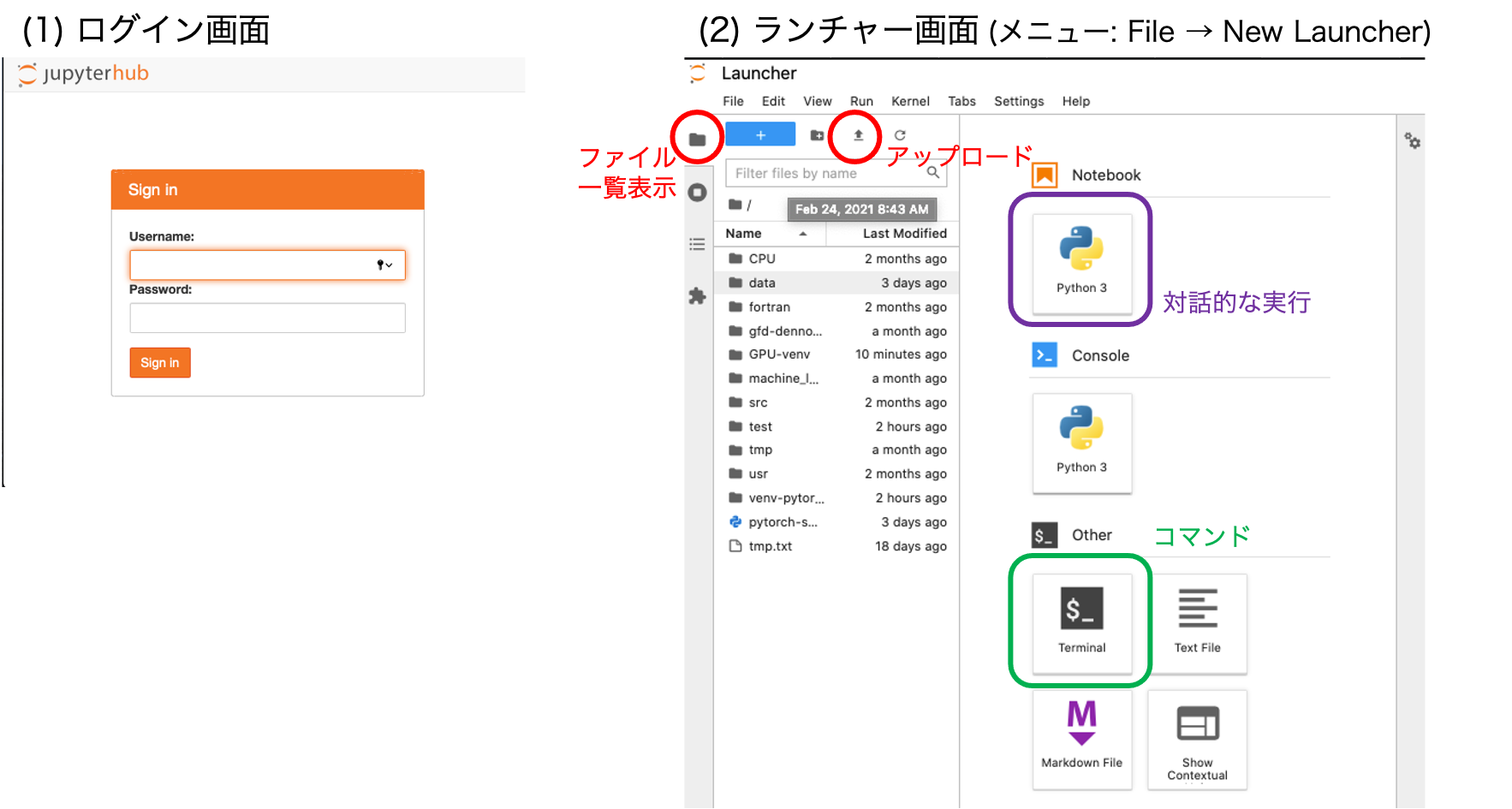
対話的な実行
本システムは多人数で共有しているので,GPU の空き状況を調べてから計算を行ってください. なお,GPU を使うプログラムが 5 分間動きが止まると自動的にカーネルのリセットがかかります. また,1 回の計算の実行は最大で 36 時間です.
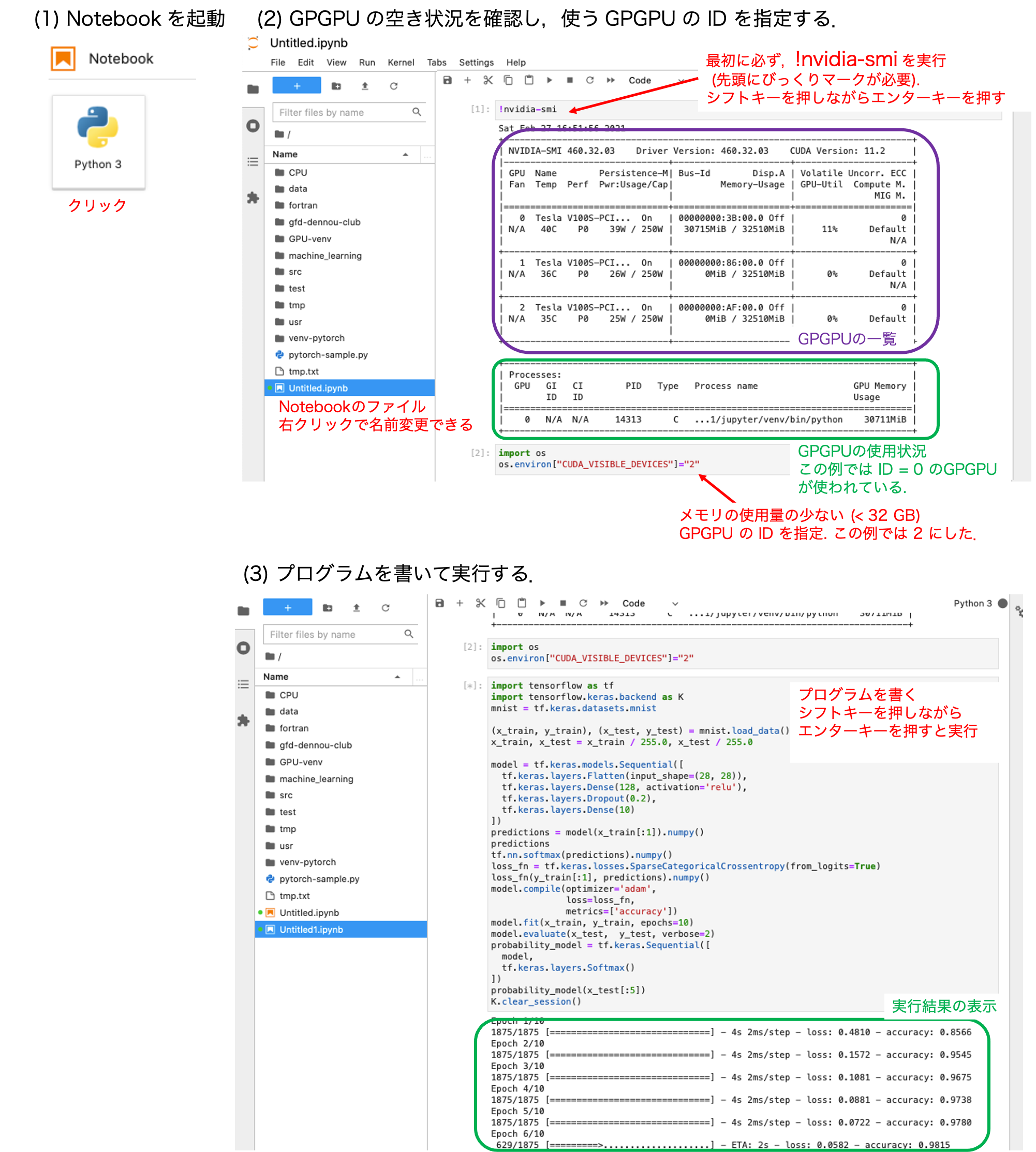
GPU の使用状態の確認
!nvidia-smi
利用する GPU の ID の指定 (以下では, ID=2 を利用)
import os os.environ["CUDA_VISIBLE_DEVICES"]="2"
テストプログラムの実行
import tensorflow as tf import tensorflow.keras.backend as K mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10) ]) predictions = model(x_train[:1]).numpy() predictions tf.nn.softmax(predictions).numpy() loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) loss_fn(y_train[:1], predictions).numpy() model.compile(optimizer='adam', loss=loss_fn, metrics=['accuracy']) model.fit(x_train, y_train, epochs=10) model.evaluate(x_test, y_test, verbose=2) probability_model = tf.keras.Sequential([ model, tf.keras.layers.Softmax() ]) probability_model(x_test[:5]) K.clear_session()
TIPS
- プログラムの実行が終わっても, Jupyter が GPGPU を握り続けてしまいます. 実行が終わったら,または,最初からプログラムを作り直した時やプログラムの実行がおかしい時などは, メニューの kernel から restart をかけてください.
- 文法ミスなどした場合には, 当該箇所が赤背景で表示されるので,適宜直してください.
- Jupyter の使い方は Google 検索するとたくさん出てきます.分からないことは検索してみてください.
ターミナルからの計算の実行
ランチャーから Terminal を選択すると,Linux でコマンドを打つのと同じことがブラウザ上で実行できます.
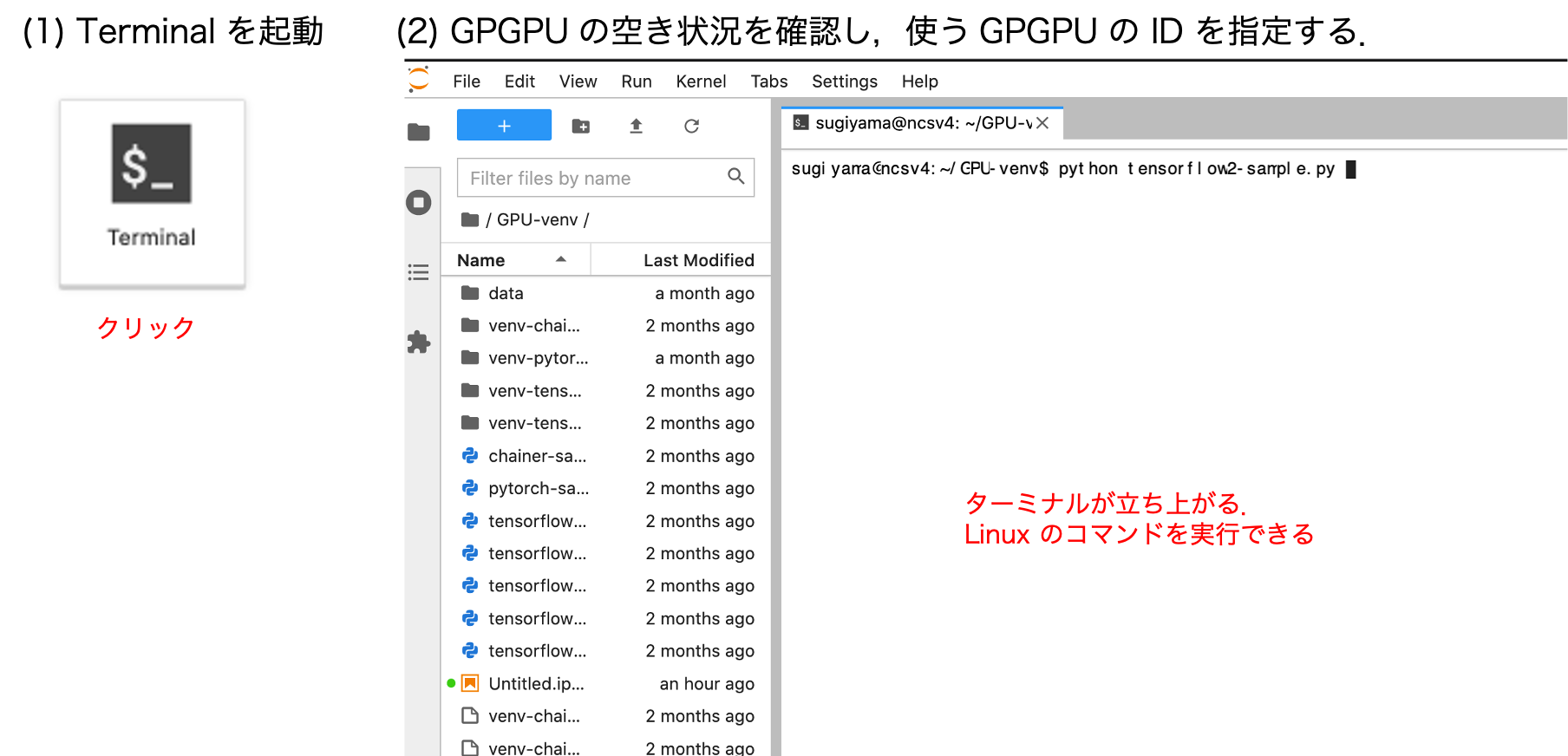
python のプログラムであれば,以下のように実行できます (以下, "$" から始まるブロックは, ターミナル上でコマンドを実行することを示します).
GPGPU の使用状況を確認
$ nvidia-smi
利用する GPGPU の ID を指定 (以下の例では ID=2 を指定)
$ export CUDA_VISIBLE_DEVICES="2"
計算の実行.
$ python /work/SAMPLES/Python-venv/tensorflow2-sample.py