昨今の計算機技術の進歩に伴い、さらに高速・高精度化された数値計算が
望まれ研究される一方で、個別のプログラムに関して詳細な情報を得る方法、
膨大な量の解析結果から研究者毎に関心のある情報を引き出す手段は、
その技術の進歩に比べて未発達であると言える。
そこで、本来なら共有可能な貴重な情報にも関わらず抜け落ちている情報、
例えば経験に基づいた実験パラメータや、
数値計算プログラム利用の際の計算例などを含め、
増え続ける情報を、効率よく有効に利用可能な仕組みを構築・整備することが
重要となってきた。
こうした状況を受け、2000年11月、伊理正夫らを中心に
知見プラットフォーム推進協議会が発足した。
この協議会は、知見プラットフォームの普及と、
知見共有のために策定したコンテンツ形式と
ソフトウェア・アーキテクチャを公開し、標準化を推進することを目的としている
。
この知見プラットフォーム構想の基となっているのが、
過去に情報処理振興事業協会(IPA)の
次世代デジタル応用基盤技術開発事業(平成10年度)において
CAMP(Collaborative Activities for
Materials Science Programs)
プロジェクトが中心となって研究開発した情報共有システムである。
同システムでは、計算科学分野において萌芽期にあるプログラムの発展の促進を狙い、
従来ソースコードの公開に留まっていたものに、
計算例や計算テクニックなどのプログラム利用に関する様々な知見を付加し、
これの蓄積・流通・活用に至る整備された環境を提供する。
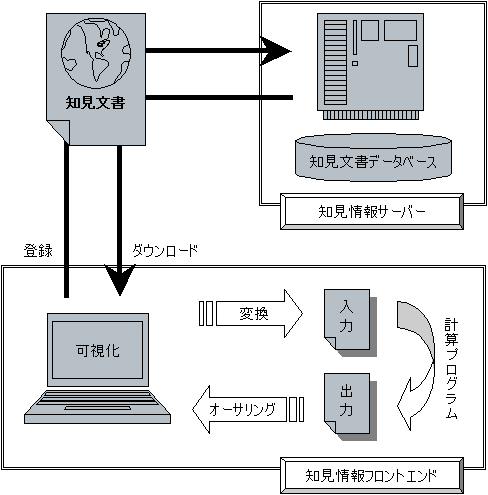
具体的には、既存の情報は知見文書と呼ばれる XML により構造化されたものに書き換え、
これをデータベースに蓄積し管理する知見情報サーバーと、
ネットワークを介した知見文書の検索・取得・登録をこなし
知見文書オーサリングツールという側面も持つ知見情報フロントエンド、
そして、計算プログラムが XML で表現された知見情報を入出力できるようにするための
XML I/O ライブラリからなる(図1)。
実証実験は、生体高分子、メッシュ生成、計算流体力学、計算物理の
4分野の研究グループで行われ、以下の有用性が確認されている(表1)。
- パラメータ設定方法などのノウハウ継承、類似ケースへの転用による効率化。
- 協働作業による効率化。
- 多種類の解析結果の集積により、類似性や多様性が容易に評価可能。
表1
| 分野 |
参加機関 |
アプリケーション |
生体高分子
京都大学:郷研究室
早稲田大学:輪湖研究室
北里大学:猿渡研究室
名古屋大学:郷研究室、垣谷研究室
大正製薬株式会社
FEDER/2
- タンパク質の立体構造エネルギー解析
- 鎖状高分子の立体構造エネルギー解析
- 基準振動解析
メッシュ生成
東京大学:杉原研究室
非構造格子メッシュ生成ソフトウェア
計算流体力学
東京大学:矢川研究室
九州大学:金山研究室
横浜国立大学:奥田研究室
MSF-TSLOW
- 非圧縮性粘性流体解析
- 3次元非定常流れ解析
- 層流、大規模問題
計算物理グループ
CAMP プロジェクト
CAMM フォーラム物理分科会
CAMP-Atami
知見プラットフォームは研究者間のコラボレーションを支援する、
知的研究基盤である。これは計算科学技術分野に限らず、
科学技術分野全般における研究開発活動を促進する上で
大きな効果が期待されると思われる。
地球惑星科学分野でも知見情報の定式化を行うことが強く要請されているが、
地球惑星科学分野内部での動きは、
地理情報学など行政サイドの必要の強い領域をのぞいては、
非常に鈍いと言わざるをえない。
これは、新たな知見情報を得ることが通常の研究活動とされ、
既存の情報を活かす組合せ方の調査、
さらにはそのための技術を開発することが、
従来、理学的研究とは見なされて来なかったことに加え、
XML 等の最新情報技術や計算機科学の動きを理解している地球惑星科学者が今だ少なく、
従って、このような研究活動に対する理解がない、
あるいは、どう評価していいかわからないことに依る。
今後さらに他分野へと範囲を拡げ発展しゆくと目される
上記知見プラットフォーム推進協議会の生成物と互換性を保つことで得られる種々の情報が、
物理・化学などの枠を超えた総合科学分野ともいえる地球惑星科学において
有用と成りうることは無論のこと、
むしろ総合的位置にあるが故に個別の学問の領域では
満たすことの出来ない知見を得ることのできる地球惑星科学こそが、
視野を拡げ積極的にその情報管理を行うべく活動すべきではないだろうか。
本研究では、知見プラットフォーム推進協議会における
流体工学・地球流体科学知見情報部会を視野に入れつつ、
知見情報の共有に必要となる技術について調査し、
地球惑星科学分野における知見情報共有システムの姿を模索したい。
なお、先駆的な試みゆえ、
地球惑星科学での応用を具体的に考える前段階としての概念的導入と整理を行うべく、
簡単な例を構成して考察を進める。
XML(邦訳すると"拡張可能な印付け言語"となるが決して一般的ではない)は、
SGML(Standard Generalized Markup Language)
[ISO 8879]
のサブセットであり、
W3C(World Wide Web Consortium)
によって作成され、その仕様が勧告されている。
これは言語を記述するための言語、即ちメタ言語であり、
言語の構造を記述する手段を提供するものである。
2001年01月現在での最新のものは、
2000年10月06日に勧告された XML 1.0 (Second Edition) である。
XML は、文書型が容易に定義でき、SGML で定義された文書が簡単に記述・管理でき、
インターネットを経由してそれらを容易に伝送・共有することを目標としている。
以下に XML 文書の例を示す。
この様に XML では、全ての情報は文字に置き換えて記録される。
XML 文書はテキスト・データである。
これはバイナリ・データと異なり人間の目で内容が確認できるという事を意味する。
しかし、従来よりみられる一般的なテキスト・データと異なり、
内容を構造化して表現することが可能となっている。
また、コンピュータもその内容を判読できるよう設計されている。
それを可能にしているのが、タグ(tag)によるマークアップである。
「XML の記法」という文字列に、それが表題であるという情報を付加するならば、
<title>XML の記法</title> のように、
不等号で挟まれたもの(ここでは <title>)
で文字列を挟む。この行為をマークアップと呼ぶ。
各部の呼称を図2に示す。
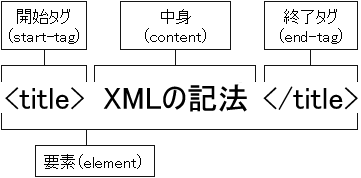
なお、要素名とは不等号に挟まれた文字列を指し、
要素(element)の型(type)を表す(図2では title)。
また要素(element)は属性(attribute)を持つことができる(図3)。

XML では、中身(content)に要素(element)を含めることで階層構造を構成する。
これにより要素間に親子関係が生じ、情報を構造化する事ができる。
このような構造は図4の様な形で視覚的に表現できる。

上に挙げた要素等は一つの例に過ぎず、
XML では要素名や属性は必要に応じて任意に設定することが可能である。
これによりアプリケーション固有の要求に合わせて機能を拡張することができる。
コンピュータは要素や属性、要素間の構造を捉えることで、
内容を判読する。
一般に、XML を用いた情報表現の長所は"分かりやすさの向上"であり、
短所は"効率の低下"である。
-
長所
-
先天的特性による長所
- テキストを扱う既存の多くのソフトウェアで容易に扱える
- 人間が直接内容を確認することが容易である
- 内容の修正も特殊なソフトウェアを必要としない
-
後天的特性による長所
-
様々な分野で多くの人々から注目されたために、
XML 文書を処理する際に必要となる概念や規格、
ソフトウェアが活発に生まれており、
それらを利用することで、
個々のプログラム作成にかかる手間を減らし、
その構造もよりシンプルなものにすることができる。
-
短所
-
文字として表現するために回りくどくなり、
従来のバイナリ・データと比べデータ量が増える。
-
文字列以外のデータは変換してから処理する必要があるため、
そのための処理工程が増える。
-
文字で表現しにくい画像データなどを取り扱いにくい。
これは直接バイナリのまま埋め込むことで回避できる。
また画像においては、
1[pixel2]毎に異なる情報として
取り扱う必要があるデータ(写真など)を除き、
図形情報として取り扱えるデータ(グラフ等)は、
後で紹介する SVG を利用することで積極的に対応できる。
ソフトウェア業界が XML に注目し、多くの期待を寄せたのは、
XML が既存の技術に比較してシンプルであったためである。
ソフトウェア業界では、
慢性的な技術者不足に悩まされていた一方で、
市場からはより大規模なソフトウェア開発を求められてきた。
開発効率を高めるために、
既存の資源を再利用可能にする技術が考え出されたが、
実際に再利用可能であるためには、
その技術が多くの開発者に理解しやすいことが望ましい。
また、開発の規模が大きくなるにつれて必要となる技術者の数は増加し、
結果、関与する技術者全体の平均的な技術力は低下する。
そこで、数人の天才だけが理解できる高級なものではなく、
多数の平凡なプログラマーが理解できる、
シンプルで簡単な概念や技術が求められた(江藤, 2000)。
こうした要求を満たす解の一つとして、
単純さと高い拡張性を兼ね備える XML は評価されている。
XML は、知見文書に求められる要件を満たすだけでなく、
そのシンプルさゆえに利用者に対する敷居が低いことが利点となるだろう。
情報は、単なるデータではない知見として整理されてなければならないが、
これは1つ1つのデータをタグでマークアップし、意味付けすることで満たされる。
既存のプログラムが知見情報を利用できるようにするためには、
知見情報を直接入出力できるようプログラムを加工するか、
プログラムが直接入出力できるよう知見情報を変換する必要がある。
単純な入出力データを扱うプログラムであれば後者で充分間に合うと思われるが、
ファイルからのデータ読み込みや標準入出力を組み合わせた複雑な仕様のプログラムの場合、
知見情報を直接入出力できることが望ましい。
XML はその柔軟性から、2つ以上の情報形式へ変換する際の、
ソースとして利用しやすい中間媒体的特性を持つ。
例えば1つの XML 形式の文書から、
WWW(World Wide Web)における情報記述用共通言語である
HTML(HyperText Markup Language)形式の文書、
表計算やデータベースなどで汎用的に用いられる
CSV(Comma Separated Value)形式の文書、
Adobe Systems 社により開発された電子文書用フォーマットである
PDF(Portable Document Format)形式の文書等へ、
簡単に変換する手段が用意されている。
これは XML で知見文書を記述すれば
既存プログラムへのデータ変換も容易であることを示唆している。
また、XML 文書をプログラムから操作するための手段も、
Java を筆頭に、C++ 、BASIC、Perl、ECMAScript
ECMA(European Computer Manufacturer Association:
ヨーロッパ電子計算機工業会)により標準化された JavaScript 。等々を対象に
複数用意されている。これらは基本的に外部ライブラリとして存在しており、
プログラムは必要に応じてライブラリにアクセスし、処理を行う。
ライブラリの仕様は開発中途ではあるが、最低限必要となる基部の仕様は完成されている。
従って開発者は、開発にどのような言語を選んでいても、
基本的な概念と知識を習得すれば、
同じ感覚で XML 文書を操作することが可能となっている。
これは XML で知見文書を記述すれば、
プログラムから直接知見文書内の情報を入出力する手段が、
豊富に用意されていることを示唆する。
関連情報、即ち履歴や参考文献などの情報を記録する際、
個々の文書内にその全てを記録すると情報が過大になる傾向があるが、
関連情報そのものではなく、その関連情報へのリンクを記録すれば良い。
既存の HTML に比べ、XML ではリンクをより柔軟に扱うことができるよう
XLink、XPointer が策定中であり、
これらを利用することで要件は充分満たされるものと思われる。
従って、XML が備える特徴は、
知見文書の記法に求められる要件を満たすのに充分なものと言えよう。
また、XML の取り扱いは専門外である多くの研究者にとって、
XML がシンプルであるという特長は、精神的労力を緩和し、
利用の際の敷居を低くすることが出来るという点で非常に有効である。
このことは、利用者とシステム開発者の境を希薄にし、
システムに対する議論を活性化させ、
ひいてはシステムの改良に繋がり利用者の使い勝手が向上するという、
好ましい循環を生み出す。
XML と同様にタグを用いて情報を表すものに
WWW における情報記述用共通言語 HTML があるが、
HTML は WWW 用に設計されているために視覚的意味付けに終始している傾向にあり、
データの論理構造と物理構造が混在した記法をとる。
データの論理構造を記述するための言語を表現するために設計された XML とは
現在は目的が異なっており、
比較競合する対象ではなくむしろ兄弟関係にある。
また、HTML は要素型を独自に定義することを許していない。
XML 自身は SGML の難解・厳格な部分を取り払い、
HTML のインターネットとの親和性を受け継いだ言語とも言える。
今日では XML を利用し、HTML を XHTML として再設計する方向にある。
XML はその拡張性の高さから、既に様々な分野から注目を浴びている。
主要な用途として、
新たなマークアップ言語の策定にメタ言語として利用すること(MathML etc.)、
情報の交換や再利用を円滑に利用できるよう書式を規格化すること(PML etc.)、
異なるシステム間で効率的に連携できるよう入出力を抽象化すること(MML etc.)、
HTML に代わる WWW 上の情報表現手段として利用すること(Compact HTML etc.)
などが挙げられる。
以下に具体例を幾つか示す。
- 医療
-
MML(Medical Markup Language):
異なる医療機関(電子カルテシステム)の間で、
診療データを正しく交換する為に考えられた規格。
-
PML(Pharmaceutical Markup Language):
PML 研究所の中橋氏が開発。
目的は、薬剤添付文書の電子管理。
- 化学
-
BIOML(BIOpolymer Markup Language):
タンパク質や遺伝子などの生体高分子等に関して、
実験情報を記述する規格。
- 電子商取引
-
BizTalk:
Microsoft を中心にフレームワークを模索。
多数の企業が XML への強い関心を示すしているが、
XML は非常に柔軟なため、XML 実装のフレームワークに
一貫性が求められる。BizTalk フレームワークは、
幅広いユーザーが一般的な手法で XML を使用できるように
するための一連のルールを実装する。
- 携帯機器
- Compact HTML(NTT DoCoMo)
- MML(Mobile Markup Language:J-PHONE)
- WML(Wireless Markup Language:KDDI)
本章では、知見プラットフォームにおける知見文書記法を紹介し、
実際に知見文書を取り扱う際に考慮すべき事柄について述べる。
知見文書は、情報を XML で構造化したものであると述べた。
これは個々の情報をタグでパッケージ化したものと表現することもできる。
知見プラットフォームにおける知見文書の構造の概念図を、図5に示す。
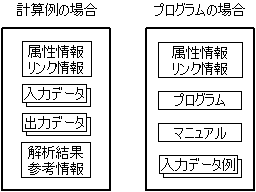
左側に計算例を、右側にプログラムを、
それぞれ知見文書として表現した場合の構造を示している。
これは CAMP プロジェクトが中心となり研究開発した
情報共有システムの場合を例にとった。
地球惑星科学分野においては、この他、
観測データや実験データを登録することが考えられる。
表2に、情報共有システムの実証実験において、
知見文書として登録された内容を示す。
表2
| 登録項目 |
内容 |
| タイトル |
知見文書のタイトル |
| 登録者名 |
氏名、電子メールアドレス、所属 |
| 改訂情報 |
改訂版の場合、元の知見文書の指定 |
| 登録内容 |
登録する知見文書の内容 |
| 登録ファイル |
登録するファイル名(複数指定可能) |
| 圧縮情報 |
圧縮して登録する場合の指定 |
| リンク情報 |
既登録の知見文書とのリンクの指定 |
| 日付 |
知見文書が登録された日付 |
実際の知見文書の例を一部、下に引用する(芦野, 2000)。
(4.2) に示した例と比較すると分かるが、
上の例では <!DOCTYPE document SYSTEM "document.dtd">
に相当する行が存在しない。
また、要素名にアンダースコア( _ )が多用されている。
以下では XML 文書の定義と検証をふまえながら、これらについて述べる。
XML 文書は、XML 宣言、文書型宣言、
XML インスタンスの3つのブロックにより構成される。
XML 文書の第1行目には、その文書が XML で記述されている旨を示す
XML 宣言を記述する。XML 宣言では、
記述に用いた XML のバージョンや文字コードなどを宣言する。
2001年01月現在、XML のバージョンは 1.0 のみであり、
基本的にバージョンの違いによる種類の差を考慮する必要はない。
XML 宣言は <? 処理命令ターゲット 処理内容 ?> という処理命令の形式をとる。
具体的には、
<? xml version=" XML のバージョン" encoding="文字コード名" standalone="yes|no" ?>
となる。ここでバージョン番号は必ず記述しなければならない。
また、文字コードの指定とスタンドアローンの指定は任意である。
文字コードは Unicode 多くの自然言語に対応可能なキャラクタセット。
cf.) http://www.unicode.org/
である UTF-8 と UTF-16 が規定値である。
スタンドアローンの指定の規定値は no である。なお、スタンドアローンに関しては後述する。
表3:主な文字コード
| 主な文字コード名 |
解説 |
ISO-10646-UCS-2
| Unicode と同一 |
ISO-10646-UCS-4
| 2バイトで表しきれなかった文字を4バイトで表現。 |
UTF-8
| UCS-2 と UCS-4 をカバー。日本語は1文字3バイトになる。 |
UTF-16
| UCS-2 と UCS-4 をカバー。現在はまだ Unicode と同じ。 |
EUC-JP
| EUC コード |
Shift-JIS
| シフト JIS コード |
ISO-2022-JP
| JIS コード |
3番目の構成物 XML インスタンスは、階層構造を持った要素の集合である。
上の例では、<C_DOCUMENT>....</C_DOCUMENT>部が XML インスタンスになる。
2番目の構成物、文書型宣言(document type declaration)は、
文書中の要素、属性などを定義するものである。
文書型宣言で定義される文書型を
DTD(Document Type Definition; 文書型定義)と呼ぶ。
DTD を外部ファイルとして用意し、それを XML 文書で利用することもできる。
文書型宣言は省略可能である。文書型宣言の例を2つ以下に示す。
これは (5.1) で例示した XML 文書を、
DTD で定義する場合に想像される文書型宣言である。
この例の内容は、あくまで筆者が XML 文書の構造を元に作り出したものであり、
一般的な文書型宣言の雰囲気を伝える以上の意図はない。
実際の (5.1) で引用した知見文書は、目的を持って文書型宣言を省略したものであり、
この文書型宣言が利用されているわけではないことに注意されたい。
これは (4.2) で例示した XML 文書の文書型宣言である。
上の例では文書型宣言の内容(DTD)が XML 文書内に存在するのに対し、
こちらは別途 document.dtd として DTD を記録したファイルを用意し、
これを文書型宣言の内容として参照している。
先に述べたように、XML では SGML と異なり、DTD の省略が許されている。
DTD の有無により、XML は下記の2種に分類される。
- Well-formed:(DTD 無)
別名、整形式。XML の規格に適合しているもの。
基本的に1つ以上の要素を含み、開始タグと終了タグの対応がとれていれば良い
(正確な定義は W3C による仕様書を参照のこと)。
全ての XML 文書は整形式を満たさなくてはならない。
整形式の XML 文書がある制約条件(DTD)を満たせば、妥当な XML 文書という。
- Valid:(DTD 有)
別名、妥当。要素と属性や文書の構造をあらかじめ定義し(DTD)、
これに適合しているもの。厳密な検証を行うことができる。
- スタンドアローン:ファイル中に必要な文書型定義が含まれるもの。
- (非スタンドアローン):定義部を外部ファイルに記述したもの。
XML がその将来を有力視された理由の一つに、
整形式の XML 文書を許したことが挙げられる。
しかし、異なる組織や研究者間で、円滑に XML 文書を交換する上で、
XML 文書の書き方のルールを曖昧さ無く表現し、
任意の XML 文書が正しい意図通りに記述されているかを検証することは、
非常に重要である。
そのためには、スキーマ言語を利用し、ルールを規定する必要がある。
XML 向けの代表的なスキーマ言語に、DTD を初めとして、以下のものが挙げられる。
- DTD (Document Type Definition)
- XML Schema
- RELAX (Regular Language description for XML)
なお、(5.1) で引用した知見文書は上のいずれも利用していない。
その代わりに、
タグの定義を独自に定義した整形式の XML 文書(タグ辞書
知見プラットフォーム関連資料に従い、タグという表現を用いる。
と呼称)を用意しており、これをもって知見文書の検証を行っていると推定される。
ここで既存の DTD が採用されなかったのは、後述する DTD の弱点に起因する。
この手法は、後で詳細を述べる XML Schema や RELAX と同じ方向性を持つと言える。
定義の手段にいずれを選ぶにせよ、その記法は (3.1) で述べた要件を満たすよう、
策定する必要がある。
先の情報共有システムでの知見文書においては、
全体を共通タグと分野別タグに二分し、
共通タグセットでは知見情報の構造定義の他、情報提供者名や登録日時といった、
分野に依らない共通項目を表現するようにしている。
- 共通タグ:接頭辞 C_
- 書誌情報:接頭辞 H_
- 概要、作者、キーワード:H_abstract, H_affiliation, etc.
- 相互連関、ハイパーリンク
- プログラムのダウンロード、実行
- 共通属性
- 分野別タグ
-
応用分野別:
接頭辞 BB_ => 生体高分子,
接頭辞 BF_ => 流体解析,
接頭辞 BM_ => 非構造メッシュ,
接頭辞 BP_ => 物質材料設計
- 数値解析プログラム依存
-
システム関係:
接頭辞 P_ => 通信プロトコル,
接頭辞 S_ => 検索,
接頭辞 E_ => 拡張機能
- その他(主にシステム関係)
- タグ辞書記述用:接頭辞 D_
- フロントエンド:接頭辞 F_
知見プラットフォーム自体が、まだ試作の段階にあり、
一般公開されていないため、上記一覧にはやや不正確な所があると思われるが、
基本的な設計方針は実際と大きく異なることはない。
ここで注目したいのは、タグを分類する際に、
その目的に応じて要素名に接頭辞を付加している点である。
知見プラットフォームのように、幅広い分野をサポートするシステムを構築する際、
1つの団体が全ての文書型定義(ここではスキーマ言語としての
DTD ではなく、定義そのものを指す;タグ辞書)を決定するのではなく、
それぞれの分野に明るい人間が集って各々文書型定義を作成し、
共通部分のみ1団体で統轄する形が現実的である。
そうした場合、共通部分を定義したもの、分野別に制定したもの、
と複数の文書型定義が1つの知見文書内に共存できなくてはならない。
XML では自由にタグが定義できるために、全く同じ名称のタグに、
定義した人それぞれが異なる意味を与える可能性があり、
こうした名前の衝突を解決しなければならない。
また、検証という面からも、どの要素がどの文書型定義により定義されているか、
明らかでなくてはならない。
接頭辞の付加は、この問題に対処すべく考え出されたものと思われる。
この記法が策定された段階では、
まだ後述する XML における名前空間の仕様
(Namespaces in XML)が整っていなかったため、
独自に解決する必要があったことも大きく関与している。
既に名前空間は1999年01月に W3C により仕様が勧告されており、
またそれに対応したソフトウェアも増えてきている。
地球惑星科学分野用の文書型定義を策定する際は、
名前空間をシステム共々考慮した形で進めて問題はないと考えている。
XML における名前空間(以降、名前空間と記する)とは、
複数の XML データ定義を混在させるための XML 拡張仕様である。
XML の仕様では、要素型が同じであるならば同じものと見なすよう
決められている。
そこでこの仕様では、名前空間(namespace)と名前空間接頭辞(namespace prefix)
という概念を XML に導入し、混在を可能にした。
実際に名前空間を利用し、(5.1) で引用した知見文書を書き改めたものを次に示す。
名前空間は URI (Uniform Resource Identifiers) を識別名に用いる。
上の例ならば、"http://www.tikenpuratto.org/tiken/common"や
"http://www.tikenpuratto.org/tiken/material"が該当する。
なお、この URI は筆者が説明のために仮に作成したものであり、
例えばブラウザでアクセスしても全く意味はない。
URI は識別名として用いているに過ぎず、該当場所のドキュメントの有無は勿論、
実際にそのホストが存在する必要もない
(ただし他者に既に利用されているものを用いてはならない)。
実際は、知見プラットフォームのサイトが完成し公開されれば、
その URI が適当であろう。
例の2行目では、DOCUMENT 要素の名前空間として
"http://www.tikenpuratto.org/tiken/common"を指定し、
その名前空間に属する要素名の接頭辞に C を用いる事を定義している。
同様に7行目では、BODY 要素に含まれる接頭辞 BP の要素が、
名前空間"http://www.tikenpuratto.org/tiken/material"に属することを定義している。
名前空間接頭辞を付けなかった場合に、
どの名前空間に属するかを指定する構文が用意されている。
これを利用すると、上の例はもう少しシンプルに表される。
ここでは2行目に
<DOCUMENT xmlns="http://www.tikenpuratto.org/tiken/common">
と記述することで、
既定の名前空間に"http://www.tikenpuratto.org/tiken/common"
を指定している。
前に触れたように、DTD は SGML の頃より用いられているスキーマ言語である。
これにより、要素の名前や順番の指定、親子関係の制限、
必須要素と任意の要素の区別などを設定する。
XML とも異なる独自の記法をとるが、XML Schema や RELAX に比べ、
簡潔に文書型を定義することができる。
しかし、XML の柔軟性に対応しきれず、以下の様な欠点を持つ。
- 名前空間をサポートしない。
- 厳密なデータ型を扱えない。
- XML と文法が異なる。
1番目の欠点により、DTD に依存した場合、
大規模な XML を利用したシステムを構築することが困難である。
2番目の欠点により、XML を取り扱う際に型チェックを行わなければならず、
プログラミングの行程が増える。
3番目の欠点により、XML の学習とは別に DTD の文法を学ばねばならない他、
DTD を操作しようと思うならば、ツールを XML とは別個に用意しなければならず、
開発コストが嵩む。
こうした問題点を解決すべく、
W3C が策定している DTD に代わるスキーマ言語が XML Schema である。
DTD の欠点を克服するために W3C により策定されているスキーマ言語である。
DTD と異なり、それ自体が XML によってコーディングされている。
そのため、一般的な XML 用ソフトウェアを用いて構文解析や編集を行うことが可能である。
XML Schema はまだ正式な勧告を受けておらず、
2000年01月現在、以下の3部で構成される。
- XML Schema Part 0: Primer
- XML Schema 機能の読みやすい記述を提供することを目的とした参考文書。
- XML Schema Part 1: Structure
- XML Schema における、構造の仕様。
- XML Schema Part 2: Datatypes
- XML Schema における、データ型の仕様。
以下に XML Schema の特長と、その問題点を挙げる。
- 特長
- 名前空間をサポートしている。
- データ型を表現可能することができる。
- それ自体をXMLで記述するので、検証が容易である。
- 問題点
-
目標とする仕様が大きすぎるため、なかなか定まらない
(Last Call の後にも 200 を越える問題点がリストされた)。
- 仕様が大きいため(約 300 頁)、対応するソフトウェアが現れない
- XML Schema 策定に携わっている者にとってさえ複雑。
なお、DTD の問題性はかなり前から指摘されており、
XML Schema の策定開始からもう2年ほど経つが、
2000年10月にようやく勧告候補となったばかりであり、
今までの難航具合を考えると、勧告に至るまでの道のりはまだ長いと思われる。
難航の理由は色々あるが、様々な分野で XML が注目されたために、
様々な分野から意見・要望が押し寄せられていることも一因と言える。
数値計算プログラムへデータを渡す際に、そのデータ型は重要となる。
これは、数値計算プログラム別に対応する入出力のデータ型テーブルを用意し、
フロントエンド側で検証するのは非効率的であり、
従って、データは単なる文字列ではなく、
自己記述的にその情報が提示される形にあることが望ましいからである。
XML Schema の特長の一つである組み込みデータ型には、
XML の DTD より継承したものと、新規に導入されたものがある。
以下に、XML Schema で新たに導入された組み込みデータ型を示す(表4)。
なお、(4.7) で紹介した MML(Medical Markup Language)では
独自にデータ型を規定している。
表4
| string |
boolean |
float |
double |
| decimal |
stimeDuration |
recurringDuration |
binary |
| uriReference |
QName |
language |
Name |
| NCName |
integer |
nonPositiveInteger |
negativeInteger |
| long |
int |
short |
byte |
| nonNegativeInteger |
unsignedLong |
unsignedInt |
unsignedShort |
| unsignedByte |
positiveInteger |
timeInstant |
time |
| timePeriod |
date |
month |
year |
| century |
recurringDate |
recurringDay |
|
| ※float |
IEEE 単精度 32 ビット浮動小数点 |
| ※double |
IEEE 倍精度 64 ビット浮動小数点 |
RELAX (Regular Language description for XML) は、
収拾のつかなくなってきた XML Schema に対する解決策として、
村田真らを中心に、日本の INSTAC (Information Technology Research and
Standardization Center) XML SWG が制定したスキーマ言語である
。
この委員会は、JSA (Japanese Standards Association)
から委託を受け、XML 関連の標準化を行っており、
JSA は RELAX Core を JIS Technical Report として発行した。
また、2000年11月に ISO/IEC の DIS (Draft International Standard)
22250-1 としてRELAX Core が発行されており、RELAX の国際的認知度は決して低くない。
RELAX は RELAX Core と RELAX Namespace からなる。
現在、仕様が公開されているのは RELAX Core のみで、
RELAX Core は1つの名前空間に属する要素とその属性を扱い、
RELAX Namespace は複数の名前空間を扱う予定となっている。
RELAX も XML Schema 同様、XML により記述されている。
また、組み込みデータ型も XML Schema を継承している。
RELAX Core の適合水準 classic は DTD と同等であり、
容易に DTD から RELAX Core を用いた表現へ移行できる。
RELAX の検証用プログラムも既に、
C++、Java、BASIC、そして後述する XSLT で用意されている。
また、プログラムは、既存の XML パーサの提供する API (後述)を利用すればよく、
RELAX 独自の API は必要としない。
従って、既存の DTD を利用したシステムは、
比較的容易に RELAX を利用したシステムへ移行することが可能である。
RELAX ほど DTD や XML Schema と適切な互換性を維持しつつ、
ある程度の環境が整っていて実用可能なレベルに達しているスキーマ言語は、
他に類を見ない。
RELAX は近い将来において、
最も有力かつ現実的な XML 用スキーマ言語と言える。
遠い将来まで、RELAX が生き残っているか否か、保証はない。
だが、RELAX から DTD、XML Schema への移行は充分可能であり、
RELAX で書かれた資産が無駄になることはないだろう。
(5.1) で引用した知見文書の構造を元に、(5.2) で文書型宣言を例示したが、
同じ事を RELAX で行ったものを以下に示す。
上記の例において、最後の 10 行ほどで、
要素型 BP_ux、BP_uy、BP_uz を定義している。
(5.2) の DTD による文書型宣言と異なる点として、
ここで type="float" としてデータ型に浮動小数点を明示していることに注目されたい。
なお、RELAX で独自に導入したデータ型は、none と emptyString の2つのみで、
RELAX におけるデータ型は、
基本的に XML Schema Part 2 で用意されているものと同一である。
知見情報を XML で表現し、知見文書として流通させるためには、
地球惑星科学分野においても、先の情報共有システムにおける"タグ辞書"に該当する、
文書型の定義が必要となる。
総合科学分野であるがゆえに、
他分野で既に設定された定義を組み合わせて用いることも可能ではある。
しかし、どの分野においてもその分野独自の情報表現は存在するものであり、
またシステムが開発途上にある現在においては、
積極的に環境を整えてゆくべきであり、
地球惑星科学分野用の文書型定義の策定が課題となっている。
実際の策定において採択するスキーマ言語は、
今のところ、RELAX が適切であると言えるが、
その名前空間の仕様を確定させる必要がある。
RELAX Namespace の仕様は、現在、
開発者用メーリングリストにおいて一部公開されており、
盛んな議論が交わされている。
仕様が早期に確定することを期待する
(2001年03月には JIS TR として RELAX Namespace が発行される予定のようだ)。
知見文書のようにデータを XML で記述した場合、
XML 形式の文書から必要な情報を取り出す、
あるいは XML 形式の文書を作成するといった操作を行う必要がある。
そのための手段として、XML を扱うアプリケーション(応用ソフトウェア)に、
XML 文書の読み込みや、その内容及び構造へのアクセスを提供するソフトウェア、
XML プロセッサがある。XML プロセッサの振る舞いは
W3C の Extensible Markup Language (XML) 1.0 (Second Edition)
にて規定されており、XML の妥当性を検証するものとしないものに分かれる。
XML パーサ(Parser)は、XML 文書をその構文に応じて解析し、
構文木を生成するプログラムである。
XML プロセッサは SGML の流れを受けており、
厳密には XML プロセッサ と XML パーサは異なるが、
SGML では重要であったその違いも、
XML ではほとんど意味をもたなくなっている。
そういう意味で、XML においては XML プロセッサと XML パーサは
同じものであるとみなして問題はないという。
本論文では、以降 XML プロセッサと XML パーサは、
同じ意味として用いる。
アプリケーションと XML 文書は図6のような関係を持つ。

XML パーサは、既に数種類公開されており、
一般にアプリケーションは直接 XML 文書を操作するのではなく、
XML パーサを操作して XML 文書を処理する。
以下に代表的な XML パーサを示す。
-
Xerces:
APACHE XML PROJECT
http://xml.apache.org/crimson/
が製作している XML パーサ。
Java 版、C 版、Perl 版が開発されている。
IBM 製パーサ XML4J(XML Parser for Java)を元に開発された。
2000年01月現在の最新 Java 版は、Xerces Java Parser 1.2.3。
-
Crimson:
Sun Microsystems 製の XML パーサ Project X の改良版。
後述する JAXP (Java API for XML Processing)
に標準で同梱されている他、APACHE XML PROJECT から入手することもできる。
2000年01月現在の最新版は、Crimson 1.1-ea2 (Early Access 2)。
-
XP:
XSLT など XML 関連技術の開発の主要メンバーである
James Clark
http://www.jclark.com/
による XML パーサ。2000年01月現在の最新版は XP Version 0.5。
XML パーサを利用するため、実際のアプリケーションは、
パーサが対応するプログラミング言語で記述するのが自然かつ有利である。
多くの XML パーサは Java 向けに書かれている。
また、ほとんどの XML パーサ自体、Java で記述されている。
これは Java が XML を扱う言語として優れていることを反映している。
Java が XML を扱う上で優れている点に、以下のものがある。
-
Java のキャラクタセットが
XML の標準のキャラクタセットである Unicode であるため、
XML で表現されたファイルを取り扱う際に、
キャラクタセットを意識する必要がほとんどないこと。
-
様々なプラットフォームへの移植に気を使わなくても良いこと。
-
こうした理由により、多くの XML 用の資源が Java で書かれており、
XML を取り扱う環境が整っていること。
一方、Java での問題点としては、
Java で作成したプログラムの実行速度が、
C++ などの他の言語で作成したプログラムに劣ること、
Java で描くツリー構築・生成のモデルが
いささか直感的ではないということ、などが挙げられる。
しかし、前者の問題は Java が登場した頃より指摘され続けていることであり、
その対策として、頻繁に用いるコードはネイティブコードへ
コンパイルするといった高速化の技術も現れているため、
大きな問題ではないだろう。また、後者の問題は Java に限ったものではなく、
主要な他言語でも同じといえる。
後者の問題が極めて重要視されるような場合、
Xi などの別の手段を検討する必要がある。
知見情報共有システムの構築においては、
上に述べたメリットの方がデメリットに勝り、
従って Java を採用すると良いと思われる。
ただし、システムの内、
既存プログラムとの連携を担う XML I/O 部は、
XML との親和性もさることながら、
既存プログラムに採用されている言語との親和性が重要となってくるため、
この限りではない。
XML パーサを規定する仕様に
DOM (Document Object Model)と
SAX (Simple API for XML) がある。
これらは共にソフトウェアから XML を操作するための
API(Application Programing Interface)の仕様である。
API 仕様と言う言葉に馴染みがないのであるならば、
XML 文書を扱うソフトウェアをプログラミングする際に用いる、
XML を扱うための関数群の定義仕様と考えて差し支えない。
これらの仕様に準拠した XML パーサであれば、
その仕様に沿った利用が保証される。
DOM は W3C により策定された、XML 文書と HTML 文書のための API 仕様である。
この仕様では、文書の論理構造及び文書にアクセスし操作する方法を定義しており、
Level 1 と Level 2 がある。
Level 1 が基本的な XML 操作法を定義するのに対し、
Level 2 ではデータの表現力にも力が置かれている(表5)。
DOM では XML 文書の構造を全て解析したのち、
その構文木を DOM ツリーの形でアプリケーションに提供する。
データを任意に操作でき、ノードの追加や編集も可能だが、
全データをメモリに保有するため、大きな XML 文書を処理する場合、
処理が重くなる傾向にある。動的な XML 操作に向いている。
表5:DOM の仕様
| レベル |
仕様書 |
機能 |
内容 |
Level 1
|
Document Object Model (DOM) Level 1 Specification Version 1.0
W3C Recommendation 1 October, 1998
|
CORE |
文書オブジェクトにアクセスしたり操作するための
オブジェクトやインターフェイスの最小限のセットを定義。
|
| HTML |
HTML 文書に特有のオブジェクト・メソッドを記述するために、
第1水準コアAPIを拡張。
主に"DOM-0"との後方互換性の問題を処理する。
|
Level 2
|
Document Object Model (DOM) Level 2 Specification Version 1.0
W3C Recommendation 13 November, 2000
|
Core |
Level 1 の CORE に、
これまで不足していた幾つかの機能を追加したもの。
|
| Views |
イベントと DOM ツリーを関連付けるための概念。
|
| Style |
スタイルシートと文書の関連づけの情報を扱う DOM Style Sheets と、
CSSそのもののオブジェクトモデルである DOM CSS からなる。
|
| Events |
"マウスボタンが押された"といった出来事をつかまえて、
あらかじめ指定した動作を実行させる機能。
|
| Traversal and Range |
Traversalは、Core で規定されるツリーに対して
アクセスするインターフェイスで、
具体的には NodeIterator、NodeFilter、TreeWalker の3つに分けられる。
Range は、DOM ツリー内にて範囲を指定する機能を提供する。
|
| HTML |
(未勧告) |
SAX は DOM 同様、XML 文書を利用したり操作したりするために
標準化されたインターフェースの一つである。
ただし W3C の仕様ではなく、
David Megginson(
http://www.megginson.com/SAX/index.html)
らが中心となって策定している。
1998年05月に仕様が決まった SAX 1 と、
2000年05月に仕様が決まった SAX 2 がある(表6)。
SAX 仕様のパーサは、イベントドリブンなパーサである。
即ち、XML 文書を順次シーケンシャルに読み込みながら、
XML のタグ(開始タグ、終了タグ、空要素タグ)を検出する毎に、
ユーザが設定した各種ハンドラを起動する。
アプリケーションからは、
SAX インターフェースで規定されたメソッドを実装したハンドラを用意することにより、
XML 文書を処理する。
文書を読み込みながら処理を行うことが出来るため、
反応が早くメモリ消費量の少ないプログラムを作成することが出来る。
文書を読み込み終わるのを待つ必要がないので、
ネットワークなどを介してドキュメントを読み込みながら作業を行うこともできる。
反面、XML 文書の編集や複雑な操作を行うことが出来ない。
静的な XML 操作に向いている。
表6:SAX の仕様
| 仕様 |
内容 |
| SAX 1 |
Parser オブジェクトを使って XML ドキュメントを解析する
インターフェースを定義する。
|
| SAX 2 |
XML Reader を使って XML ドキュメントを解析する
インターフェースを定義する。
XML Reader は Parser と違って名前空間をサポートする。
|
| SAX 2 Extension |
拡張ハンドラ(LexicalHandler, DeclHandler)
インターフェースを定義する。
|
以上のように、DOM と SAX には一長一短の特徴があるため、
状況に応じて適切に使い分ける必要がある。
以下にあてはまる場合は SAX を、そうでなければ DOM を利用すると良い。
- 文書要素を出現順に従って処理する場合
- 特定の文書要素しか処理の対象にしない場合
- DOM を構築するための記憶領域を節約する必要がある場合
知見情報共有システムにおいては、
知見情報フロントエンドでは柔軟な操作が求められるため、
DOM が適切であろう。
一方、知見情報サーバにおける知見検索などでは、
その情報量の多さから軽快な SAX が適切であろう。
実際にどのパーサを利用するか決定するのは、
いずれのパーサも開発段階にあるため難しい。
(6.2) で挙げた Xerces、crimson は、
いずれも DOM 及び SAX に対応している。
しかし、こと DOM プログラミングにおいて、
XML ドキュメントの生成や、DOM ツリーの生成は、
DOM の仕様あるいは標準インターフェースで定義されていないため、
XML プロセッサ固有の処理に依存するか、自前で用意しなければいけない。
これは例え DOM に準拠したパーサであっても、
あるパーサから別のパーサへ乗り換える際に、
システムに大きな変更を加えなければならない可能性が、
潜在的に存在することを意味する。
これは XML を取り巻く世界が枯れておらず、刻々と変化することを考えると、
非常に不自由であると言わざるをえない。
JAXP(Java API for XML Processing)は、
そうした問題を解消すべく、
数ある XML パーサを統一的に扱う Java のための機構である。
JAXP は ファクトリ方式と呼ばれる、
XML パーサをプラグイン化して取り扱う方法により、
Java での XML パーサの生成方法や呼び出し方法を統一する。
即ちラッパークラスを用意することで、
利用者側へのインターフェースを統一し、
各パーサ間の違いをそこで吸収させている(図7)。
従って JAXP を通せば、
XML パーサは JAXP 標準の crimson だけでなく Xerces も利用できる
(パーサを組み込んでしまえば、共通の API で利用できる)。
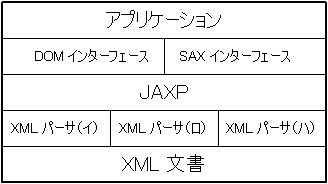
2001年1月現在の最新版 JAXP は、Ver.1.1ea2(Early Access 2) であり、
XML パーサとして crimson、XSLT パーサとして APACHE XML PROJECT の Xalan が
同梱されている。
現在は、まだ個々のパーサを直接利用するアプリケーションが多いが、
将来的にはほとんどの XML を扱うアプリケーションは、
JAXP を利用することになるだろう。
(4.5) において、
XML は中間媒体的特性を持つため、
XML で知見文書を記述すれば、
既存プログラムへのデータ変換も容易であると述べた。
XML 文書の変換の目的で、
XML パーサを利用した XML 文書を他形式のデータへ変換するプログラムを作ることは、
勿論、可能である。しかし、XML には、
もっと容易に変換を行うことの出来る手段が用意されている。
それが XSLT (XSL Transformation) である。
XML 文書で記述されるのは構造であり、見た目の情報(スタイル)は
含まれない。そのため XML 文書を適切な形で表示するための
スタイル指定言語として XSL (eXtensible Stylesheet Language) が考案された。
XSLT は、XSL を構成する2要素の内の1つとして W3C より勧告されており(Ver.1.0)、
XML 文書を他の XML 文書や HTML 文書などに変換するための技術である。
XSL を構成するもう一方の要素は FO (Formatting Objects) で、
こちらはまだ仕様が固まっていない。
XSL:FO を利用すると、例えば XML 文書から容易に PDF を生成することもできる。
以下に代表的な XSLT プロセッサを示す。
-
Xalan:
APACHE XML PROJECT が製作している XSLT プロセッサ。
Java 版、C++ 版が開発されている。
2000年01月現在の最新 Java 版は、Xalan-Java version 1.2.2。
なお、JAXP を利用した Xalan-Java version 2.0.D06(β版)もある。
-
XT:
XSLT など XML 関連技術の開発の主要メンバーである
James Clark による XSLT プロセッサ。
Java 版の他、Microsoft Windows プラットフォームで
実行可能なバイナリも公開されている。
XSLT はスタイル指定のための変換が本来の目的なため、
完全に汎用的な変換を目指した言語ではない。
XSLT は XML 文書を先頭から順に解析し、
変換対象となる要素や属性を見つけ次第、
指定された構造に順次書き換えて行く、という方法をとる。
複数ファイルへの出力が行えない、
一度定義した変数の値を変更することができない、
複雑な操作が行えないなどの制限はあるが、
それでも、構造を表現する形式の大抵のデータと XML 文書間で、
変換を行うことができるため、ほとんどの場合、XSLT で充分だろう。
参考のため、
XSLT と一般的なプログラミング言語の機能との対応を下に示す(表7)。
なお、これは XSLT が持つ雰囲気を、
従来のプログラミングの見地から理解する事を助けるために比較したものであり、
実際の動作が完全に対応するわけではないことに注意されたい。
詳細な解説は XSL Transformations (XSLT) Version 1.0
W3C Recommendation 16 November 1999 を参照のこと。
表7
| 一般的なプログラミング言語 |
XSLT |
| 変数 |
xsl:variable 要素で定義し、
xsl:value-of 要素などで値を利用する。
|
| 選択構造 |
xsl:if 要素、xsl:choose 要素 |
| 繰り返し構造 |
xsl:for-each 要素 |
| 副関数(サブルーチン) |
xsl:telmplate 要素を name 属性付きで定義し、
xsl:call-template 要素で呼び出す。
引数は xsl:param 要素で指定する。
|
| パターンマッチ |
xsl:template 要素の match 属性、
xsl:apply-templates 要素や
xsl:copy-of 要素などの select 属性。
|